The Hallucination Loop: How AI Risks Reinforcing Its Own Errors


If you've ever used a microphone too close to a speaker, you know the result: that awful, escalating screech. That’s an audio feedback loop — your voice gets amplified, cycles through the system, and spins out of control faster than it can be corrected.
Now imagine the same phenomenon, but with text. That’s where we’re heading with large language models (LLMs).
The Slow Cycle: LLMs Reading Their Own Outputs
Today, most LLMs are trained on vast amounts of text collected from the open web. Some companies run their own crawlers, others partner with established search engines, and all of them rely on Common Crawl, an open repository with roughly 300 billion pages.
On top of that, exclusive partnerships expand access. One of the most prominent was Google’s 2024 deal with Reddit. Google was quite open about the purpose:
With the Reddit Data API, Google will now have efficient and structured access to fresher information, as well as enhanced signals that will help us better understand Reddit content and display, train on, and otherwise use it in the most accurate and relevant ways.
Source: https://blog.google/inside-google/company-announcements/expanded-reddit-partnership/
The open web was — and to a large extent still is — an invaluable source of text-based knowledge. But increasingly it’s filled with AI-generated content: blog posts, SEO filler, automated news blurbs, product descriptions, and Q&A pages.
This creates what we might call the slow hallucination loop:
- LLM generates text — A model like GPT or Gemini writes an article, blog post, or answer.
- Text gets published — It appears on a website, indistinguishable from human writing.
- Future LLM training — Another model is trained on that text.
- Degraded knowledge — Errors and hallucinations accumulate, diversity is lost.
- New outputs based on old outputs — The loop closes.
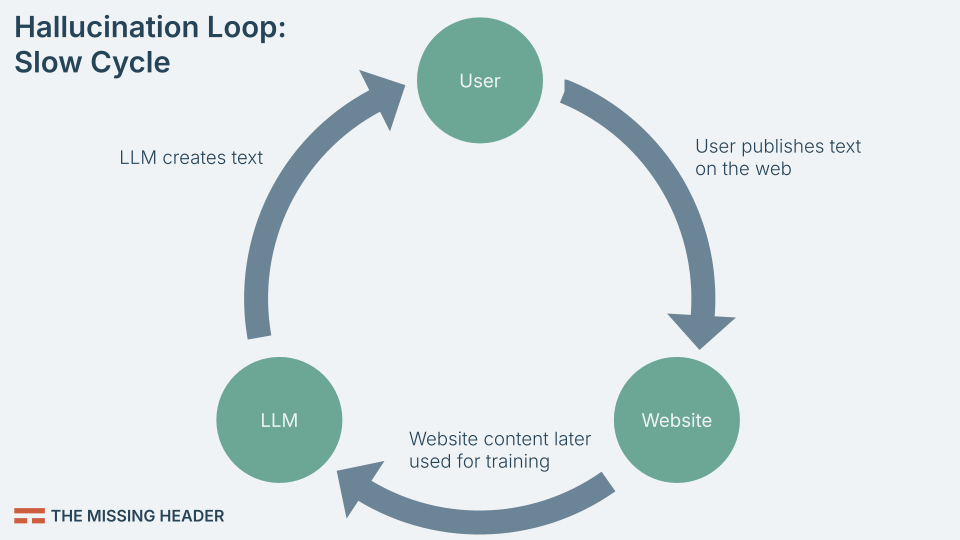
Right now, this cycle is slow. Training runs typically happen on a yearly or half-yearly cadence. AI companies filter out low-quality content. And human-written material still outweighs AI-generated text.
But the principle is clear: AI is beginning to learn from itself. And when systems recursively consume their own outputs, quality tends to spiral downward — just like audio feedback.
In the early days of the LLM boom, mostly small publishers experimented with AI content, often on low-profile domains. The influence of this feedback content was minor, and filtering it out was relatively easy. But as established organizations deploy LLMs for large-scale publishing on trusted domains, the influence will grow exponentially.
Side Note: Two years ago, I attended an SEO conference where a speaker demonstrated a system that could publish one million web pages within a few hours — fully automated, from keyword research to publishing. The process even included simple checks to avoid obvious errors like using the wrong language. This was just one developer with technology that’s already two years old. Imagine what’s possible today.
The Fast Cycle: LLMs Writing Into Databases
Even this slow cycle carries risks. But new developments are speeding things up dramatically. With LLMs now integrated directly into mainstream tools like Excel, they’re no longer just producing text for the open web. They’re writing data straight into organizational systems.
Combine that with protocols like the Model Context Protocol (MCP), and you get a shortcut that feeds LLM output back into the models themselves — this time not as “just text,” but as trusted facts.
Here’s what that looks like:
- LLM suggests data — In Excel, you ask Copilot to “fill in missing customer regions.” It makes its best guess.
- Database update — Those values are written into your company’s database.
- Database treated as fact — Future queries, dashboards, and reports rely on it.
- MCP integration — The database is exposed back to the LLM as context.
- Reinforced errors — The hallucination is now part of the model’s “trusted” inputs.
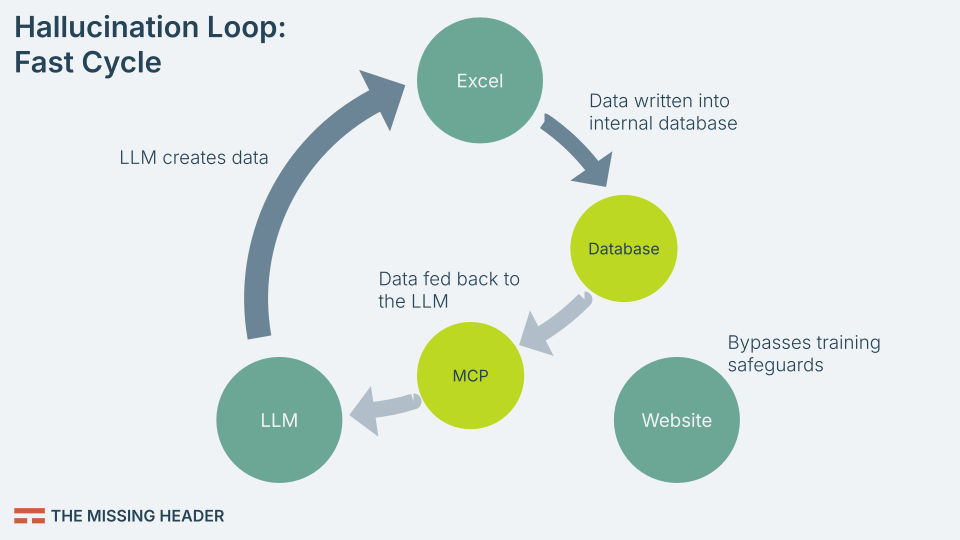
This shortcut creates a fast hallucination loop. Instead of years between error creation and re-ingestion, the cycle could close within hours. And worse: once a false entry lands in a trusted database, it gains authority. We treat internal databases as ground truth, not speculation. As soon as something is stored there, it can flow outward — powering APIs, content creation, or even regulatory filings.
Microsoft seems well aware of the risks. In the official documentation, they explicitly include a section on “When NOT to use the COPILOT function”, warning against:
Tasks with legal, regulatory or compliance implications
Recent or real-time data
Source: https://support.microsoft.com/en-us/office/copilot-function-5849821b-755d-4030-a38b-9e20be0cbf62
Why This Matters
The danger isn’t just that models get dumber. It’s that hallucinations get institutionalized.
- Inside companies: Imagine sales forecasts built on invented customer data, or financial models distorted by fabricated revenue entries. Once in a database, hallucinations propagate through reports, strategy decks, and executive decisions.
- Across industries: If multiple organizations connect MCP-enabled databases to LLMs, whole sectors could start echoing the same false “facts.”
- At the societal level: Public knowledge bases — Wikipedia, government datasets, scientific repositories — could be gradually infiltrated by AI-generated errors, which then cycle back into LLMs relied upon by millions.
The loop becomes self-reinforcing. Each round strengthens the illusion that the invented information was always true.
And Why This May Become Even Worse
So far, we’ve looked at the context of the open web. But that metaphor is fading.
As Google argued in a court filing just days ago: “The fact is that today, the open web is already in rapid decline.” (Source: 1:23-cv-00108-LMB-JFA / Document 1664)
Instead, platforms dominate — mostly mobile apps communicating with proprietary servers, APIs, and increasingly AI agents. These systems are already beginning to talk to each other, often without human oversight. And yet they are shaping the decisions we make: which restaurant we visit, which hiking trail we try, even which car we buy.
Possible Mitigations
There are reasons not to panic — at least not yet. Model developers are aware of the problem and have introduced some countermeasures:
- Filtering synthetic data before training (though filters are imperfect).
- Using curated, human-written datasets (though expensive and limited).
- Human oversight in critical systems (though often bypassed in everyday use).
- Hybrid models that balance generative outputs with retrieval-based fact sources.
But the incentives are misaligned. Generating synthetic text is cheap. Curating diverse, high-quality human data is costly. Left unchecked, the easier path will dominate.
The Bigger Picture
The hallucination loop is fundamentally a story about data integrity. In the age of LLMs, the boundary between “generated” and “real” is dissolving. Once hallucinations enter authoritative systems, they stop being obvious errors and start becoming structural truths.
This is why it’s worth paying close attention to where these loops are forming. The web already has one. Your company’s Excel files may be the next.
And if we don’t manage them, the screech of feedback won’t just be in our speakers — it will be in our databases, dashboards, and decisions. Not just inside a single company, but across society as a whole.
The first generation of LLMs amazed us by predicting words convincingly. The next challenge is making sure they don’t predict themselves into a corner.
Problems of the Slow Loop (Even Without the Shortcut)
Even if you’re skeptical that companies will fully embrace MCP integrations, the slow hallucination loop alone still poses risks:
- Loss of diversity — Human creativity gets diluted as AI-generated filler dominates training sets.
- Homogenization — Language converges toward predictable, bland phrasings.
- Error fossilization — Once an AI-generated mistake spreads widely, future models inherit it as “fact.”
- Bias amplification — Social and cultural biases get magnified with each cycle.
- Knowledge stasis — Instead of absorbing new human insight, models endlessly remix their own outputs.
In other words: even the slow loop degrades quality over time. The fast loop institutionalizes errors almost immediately. No matter which loop prevails, we — as data engineers and as citizens — need to pay close attention to the risks they create.
Thanks for reading,
Stefan



